「SFA・CRMに同じ会社が複数のレコードで登録されている」「商号の表記ゆれで重複チェックが効かない」「データクレンジングと名寄せは何が違って、どちらから手を付ければいいのか分からない」——営業データの整備に向き合う担当者なら誰もが直面する疑問です。結論として、データクレンジング(個々のレコードの修正)を先に実施してから名寄せ(複数レコードの統合)に進む順序が、データ品質を引き上げる王道です。
この記事では、名寄せとデータクレンジングの定義・違い・実施順序から、具体的な手順、ツール選定のポイント、SalesNowを使った自動化、そしてSalesNow MCPによる自然言語からのクレンジング・名寄せまでを順に解説します。読み終える頃には、自社のデータ整備をどう設計・運用すればよいかが明確になります。
名寄せとは?データクレンジングとの違いを分かりやすく解説
名寄せとは、複数のシステムや部門に分散した同一企業・同一人物のデータを、一つのレコードに統合する処理のことを指します。営業・マーケティング・カスタマーサクセスなど複数の部門がそれぞれSFAやCRMにデータを入力すると、同じ企業の情報が重複・分散してしまう問題が生じます。名寄せはこの「バラバラになったデータを正確に一本化する」作業です。
一方、データクレンジングとは、データの表記揺れ・誤字・欠損・フォーマット不統一などを修正し、データ品質を向上させる処理のことを指します。「株式会社○○」と「○○株式会社」「㈱○○」のような表記揺れ、電話番号のフォーマット不統一(ハイフン有無)、住所の省略・誤記などが対象となります。
名寄せとデータクレンジングの違いを整理する
| 比較軸 | 名寄せ | データクレンジング |
|---|---|---|
| 目的 | 同一エンティティのデータを統合する | データの品質(正確性・一貫性)を改善する |
| 対象問題 | 重複レコード、分散データ | 表記揺れ、欠損、フォーマット不統一、誤字 |
| 処理内容 | マッチング→統合(マージ) | 修正・補完・標準化 |
| 実施タイミング | データ統合時・定期的 | データクレンジングは名寄せ前に実施するのが一般的 |
| 必要性 | SFA・CRM活用の前提 | 名寄せ精度を高めるための前処理として必須 |
名寄せとデータクレンジングは独立した処理ではなく、セットで実施するのが一般的です。データクレンジングで表記を統一してから名寄せを実施することで、マッチング精度を大幅に高めることができます。SalesNowはこの2つの処理を自動化し、国内1,400万件超の企業データを基準データとして高精度な名寄せを実現しています。
企業データベースの種類や選び方については企業データベースとは?種類・活用方法・おすすめサービスを徹底解説で詳しく解説しています。
名寄せが必要な理由:データ品質が営業成果を左右する
名寄せが必要な理由とは、SFAやCRMのデータ品質が営業活動の精度・効率・成果に直結するからです。データが重複・欠損・不整合の状態では、どれほど優れた営業戦略を描いても実行段階で機能しません。
名寄せ・クレンジング不足が引き起こす問題
- 重複アプローチ:同一企業に複数の営業担当者がバラバラにアプローチし、顧客体験を損ない信頼を失う
- 分析精度の低下:重複データを含む状態では、受注率・商談数・チャネル別パフォーマンスが正確に分析できない
- マーケティング施策の浪費:同一顧客に重複したメール・広告が配信され、コストと信頼を同時に失う
- SFAの活用率低下:「SFAに信頼できるデータがない」と担当者が感じると、入力率・活用率がさらに下がる悪循環に陥る
- ターゲティング精度の劣化:ABM(アカウントベースドマーケティング)は正確な顧客データを前提とするため、名寄せ不足が直接的な施策失敗につながる
SalesNow導入企業の多くが、名寄せによるデータ整備を起点として営業活動を変革し、商談数2.3倍・売上1.5倍という成果を実現しています。データ品質は「営業のインフラ」であり、すべての施策の前提条件です。
名寄せが特に重要な組織パターン
以下のいずれかに当てはまる組織は、名寄せを最優先課題として取り組む必要があります。
- SFA・CRMにデータが10万件以上登録されている
- 複数の部門(営業・マーケティング・カスタマーサクセス)が別々のシステムで顧客データを管理している
- M&Aや組織再編があり、異なるシステムのデータを統合する必要がある
- マーケティングオートメーション(MA)を活用し、顧客スコアリングを正確に行いたい
- 営業担当者が「SFAのデータを信頼していない」と発言している
名寄せ・データクレンジングの具体的な手順
名寄せとデータクレンジングの手順とは、データの現状調査→クレンジング基準の設定→クレンジング実施→マッチング→統合→品質確認→継続メンテナンスという段階的なプロセスのことです。
Step 1:データの現状調査(データプロファイリング)
まずSFAやCRMのデータを棚卸しします。重複しているレコード数・欠損率・表記揺れの頻度・外部データとの乖離などを把握します。この段階で「どの程度のデータ品質問題があるか」を定量的に把握することが重要です。
Step 2:クレンジング基準の設定と実施
表記揺れのルール(株式会社の表記統一・電話番号のフォーマット・都道府県の省略ルールなど)を定めてから、一括でクレンジングします。Excelなどの手作業では件数が多いほど精度が落ちるため、ツールを活用することが現実的です。エクセルで名寄せする具体的な手順と限界については別記事で詳しく解説しています。
Step 3:名寄せ(マッチング・統合)
クレンジング済みのデータを使って、同一企業・同一人物のレコードを特定(マッチング)し、一つに統合(マージ)します。マッチングキーとしては「法人番号」「電話番号」「企業名+所在地の組み合わせ」などが使われます。法人番号を共通キーにすることが、最も精度の高い名寄せにつながります。名寄せロジックの設計手順とアルゴリズムについても参考にしてください。SalesNowは法人番号を基準に名寄せを行うため、高精度な統合が実現できます。
Step 4:品質確認と継続メンテナンス
名寄せ完了後も、新規データが追加されるたびにデータ品質が劣化していきます。月次・四半期ごとの定期的なクレンジング・名寄せサイクルを設けることが、データ品質の継続的な維持に不可欠です。SalesNowと連携することで、この継続メンテナンスを自動化できます。
名寄せツールの選び方と比較ポイント
名寄せツールの選び方とは、自社のデータ規模・既存システムとの連携可否・法人番号対応の有無・継続的な自動化の実現可否という4つの軸で評価することを指します。具体的なツール比較は「名寄せツール比較おすすめ10選」もあわせてご覧ください。
名寄せツール選定のチェックポイント
| チェック項目 | 確認内容 |
|---|---|
| 法人番号対応 | 法人番号を共通キーに使えるか(最も精度が高い) |
| SFA連携 | Salesforce・HubSpotなど既存SFAとの標準連携があるか |
| 自動化・継続メンテ | 定期的な名寄せを自動実行できるか |
| データ補完機能 | 欠損情報を外部データベースから自動補完できるか |
| 処理件数・スピード | 自社のデータ規模(万件〜数百万件)に対応できるか |
| サポート体制 | 初期設定・運用フェーズのサポートが充実しているか |
手動(Excel)vs ツール活用の比較
| 比較軸 | 手動(Excel) | 名寄せツール(SalesNow等) |
|---|---|---|
| 処理件数 | 数百〜数千件が限界 | 数万〜数百万件に対応 |
| 精度 | 人為的ミスが発生しやすい | 法人番号基準で高精度 |
| 工数 | 大量の時間・人員が必要 | 自動化により大幅削減 |
| 継続性 | 定期的に手作業が必要 | 自動的に継続メンテナンス |
| データ補完 | 外部データとの照合が困難 | 1,400万件超のDBから自動補完(SalesNow) |
SalesNowで実現する名寄せ・データ整備
SalesNowは、国内1,400万件超の企業・組織データベースを基準データとして、Salesforce・HubSpotなど既存SFAのデータを自動で名寄せ・クレンジングするセールスインテリジェンスツールです。名寄せ機能はSalesNowのコア機能の一つであり、「整備から行動まで一気通貫」という価値提案の起点となっています。
データ整備の次の一歩として、不足した企業情報を補うデータエンリッチメントについては「データエンリッチメントとは?意味・手法・進め方と実例」で詳しく解説しています。
SalesNowの名寄せが選ばれる理由
① 法人番号基準の高精度名寄せ
SalesNowは法人番号を共通キーにした名寄せを実施します。「株式会社A」「A株式会社」「㈱A」など、表記揺れがあっても同一法人として正確に統合できます。名称や電話番号の揺れに左右されない、最も信頼性の高い名寄せ方式です。
② Salesforce・HubSpot標準連携
SalesNowはSalesforce・HubSpotとの標準連携機能を提供しており、既存のSFAデータにSalesNowのデータを自動付与・名寄せできます。API連携の設定が完了すれば、追加の手作業なく継続的にデータが整備されます。
③ 欠損情報の自動補完
SFA内の企業レコードに欠損している情報(業種・従業員数・売上規模・電話番号・住所など)を、SalesNowの1,400万件超のデータベースから自動で補完します。これにより、ターゲティング精度や分析精度が一段と向上します。
④ 継続的なデータ鮮度の維持
企業情報は絶えず変化します。移転・合併・社名変更・組織変更などに対応するため、SalesNowは継続的にデータを更新しています。SFA連携を通じて、常に最新情報が反映された状態を維持できます。
営業組織において「データ整備は営業の仕事ではない」と思われがちですが、現実には精度の悪いデータが営業活動の質を根本から損なっています。SalesNowの名寄せ機能を活用することで、このデータ整備の工数を大幅に削減しながら、SFA・CRMのデータ品質を継続的に高いレベルで維持することが可能になります。名寄せ後のデータを営業現場で活用するための管理・運用方法については「営業リスト管理の方法|SFAと連携して商談化率を高める管理術」もあわせてご覧ください。
実装例1:SalesNowスコア×AIで名寄せを自動化する(GAS×Gemini)
SalesNowのカスタマーサクセス担当による自社内の運用検証では、名寄せ未完了の633件(複数候補361件+候補なし272件)に対して、3段階のフィルタリングを適用することで422件(約67%)を自動で特定・名寄せできました。「人が頑張って名寄せする」運用から「データとAIを前提に名寄せが進む」運用構造への転換事例として、設計の核となる仕組みを順に解説します。
この検証の起点となったのは、SalesNowが各企業に付与する「SalesNowスコア」(企業の活発度を100点満点で示す独自指標)です。会社情報の更新・従業員数推移・求人出稿・ニュース/プレスリリース配信・上場状況の5データから算出されるこのスコアを「複数候補から1社を選ぶ判断材料」として使うことで、機械的な確度が大幅に上がりました。
初期データと3段階フィルタリングの全体像
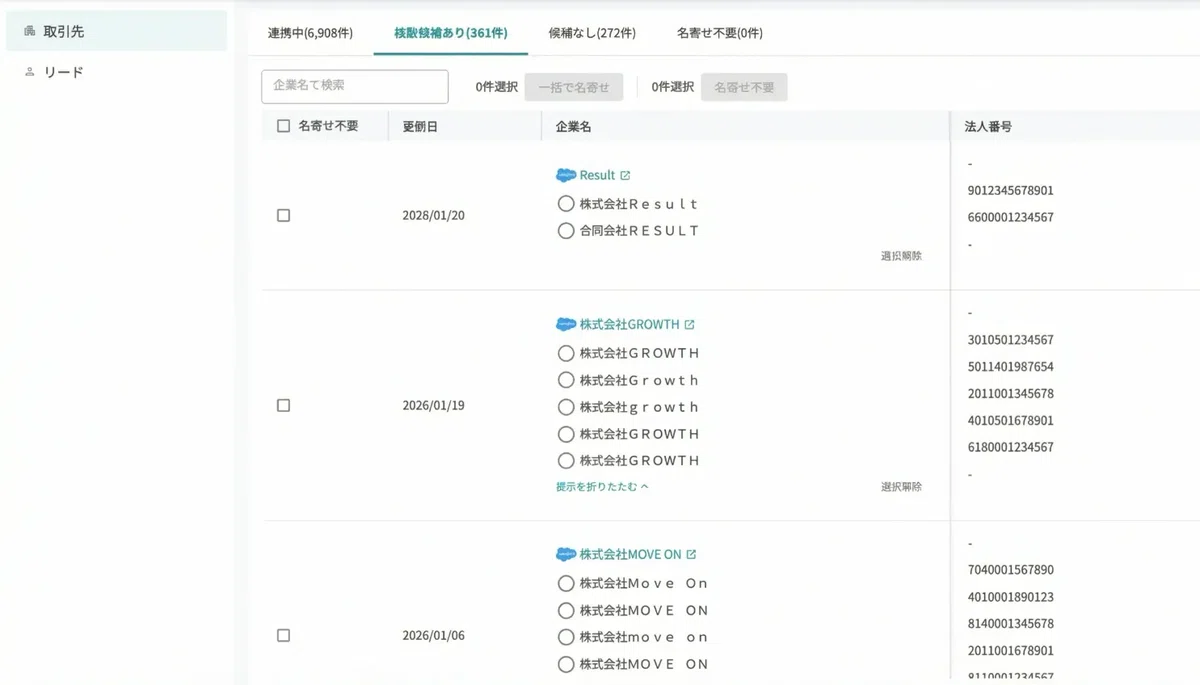
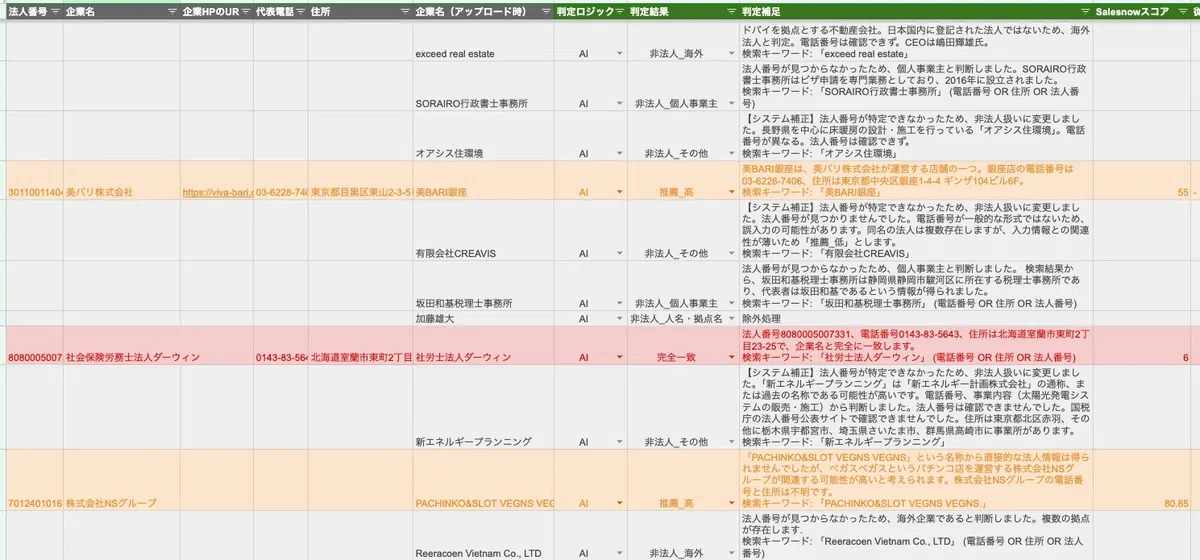
検証時点でのデータ件数は、名寄せ完了済み6,908件に対して未完了が633件。内訳は「複数候補が表示されているが1社に絞れない」361件と「候補なし(SalesNow上で対応企業が見つからない)」272件です。これに対して以下の3段階で順に判定をかけました。
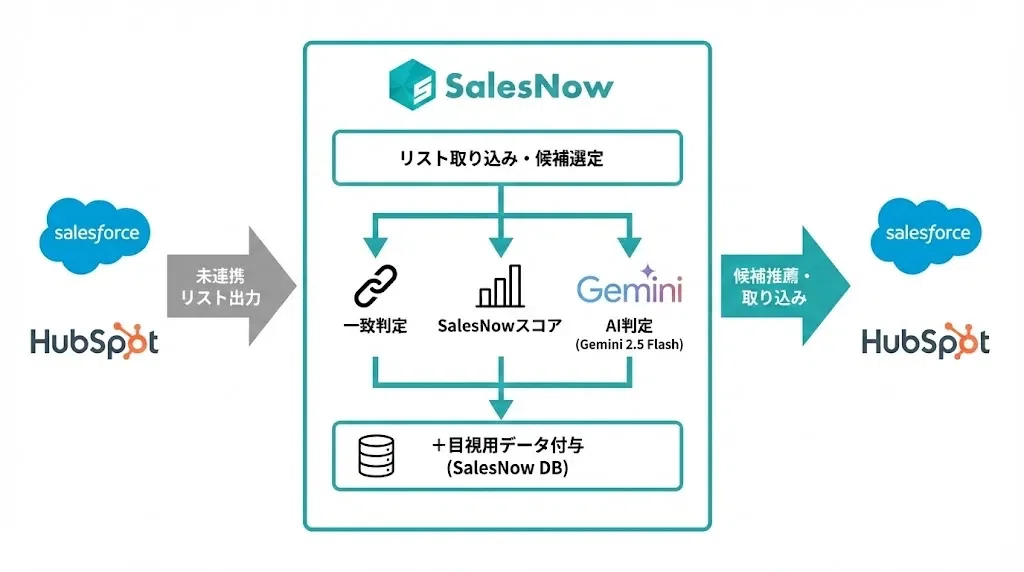
- 一致判定:完全一致/部分一致が1件のみ存在する場合に採用
- SalesNowスコア判定:複数候補がある場合は、SalesNowスコアが最も高い企業を推薦
- AIリサーチ判定:候補なしのケースで、Googleスプレッドシート×GAS(GoogleAppScript)×Gemini 2.5 Flash(Grounding機能搭載)の組み合わせで「店舗名→運営元法人」のような推定を実行
最終的に内訳は、完全一致18件・部分一致2件・SalesNowスコア推薦351件・AI推薦51件・AI非法人判定200件となりました。「AI非法人判定」はレコード自体が法人ではなかった(個人事業主・店舗単位のレコード等)と判定されたケースで、これ自体も「次にどう運用するか」の意思決定材料になります。
STEP1:一致判定(完全一致/部分一致が1件のみ)
未完了レコードに対してSalesNow APIを呼び、検索結果を取得します。完全一致または部分一致の結果が1件のみであれば自動で確定。スプレッドシート上で根拠と共に値を埋めます。

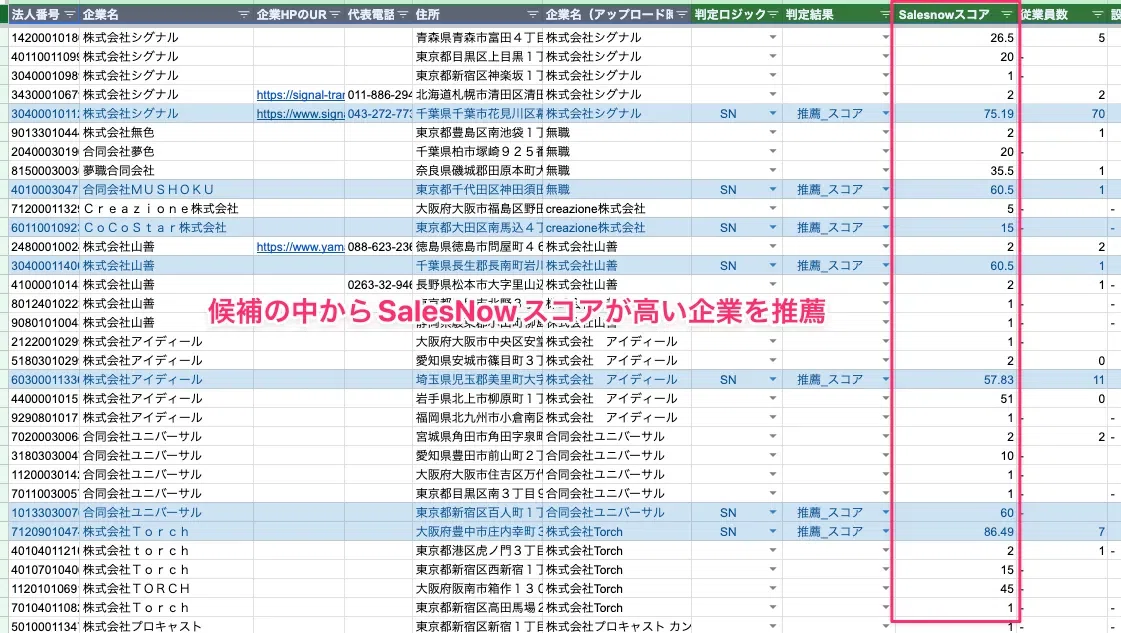
STEP2:SalesNowスコア判定(複数候補から最高スコアを推薦)
SalesNowで複数候補が返ってきたケースでは、各候補のSalesNowスコアを比較し、最高スコアの企業を推薦します。実運用上、「同名企業が複数あって人手では判断できない」という典型的なボトルネックを、データ起点で機械的に解消できる箇所です。
STEP3:AIリサーチ判定(候補なしのケースをGeminiで推定)
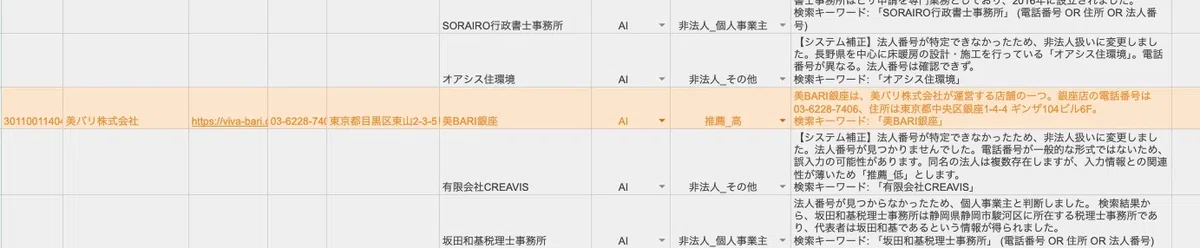
SalesNow側で候補が出ないケースは、店舗名・サービス名のみが入力されている場合が多くを占めます。ここで、Gemini 2.5 FlashのGrounding機能(Google検索結果に基づく回答生成)を呼び出し、「店舗名→運営元法人」を推定。例えば「美BARI銀座(食べログ掲載店)→運営元:株式会社カカクコム」のような推定をAIが行います。
判定根拠を出力することで「失敗を次判断につなげる」設計
本実装の特徴は、判定結果だけでなく「なぜその判定になったか」の根拠を毎回出力している点です。SalesNowスコア・従業員数・次点候補とのスコア差分・AIの推論プロセスなどを併記することで、後から「この判定は正しかったか」を人が検証できます。
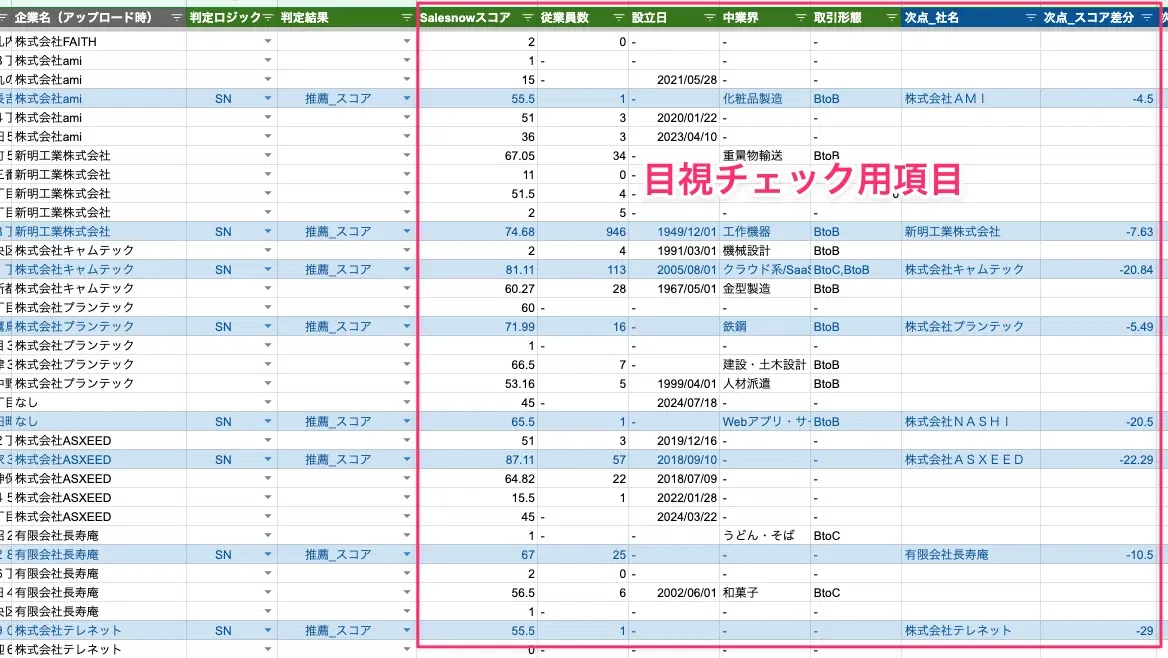
「AI非法人判定」のケースで「店舗単位レコードを法人レコードに統合しない/別管理する」といった判断や、「複数候補で次点とのスコア差が小さい場合は人手レビューに回す」といった運用フローを、根拠ログから設計できます。データ活用の「失敗パターン」を蓄積する仕組みとしても機能します。
実装例2:HubSpot×Insycleで会社レコードを10ステップで一括マージする
HubSpotに専用アプリ「Dedup by Insycle」をインストールし、SalesNow連携で付与されたJCコードをキーに会社レコードを一括マージする実装手順です。重複の検出から本番マージまで10ステップで実行でき、「親子会社の保護」「マージ上限設定」「Preview検証→本番」の三段構えで誤統合事故を防ぎます。
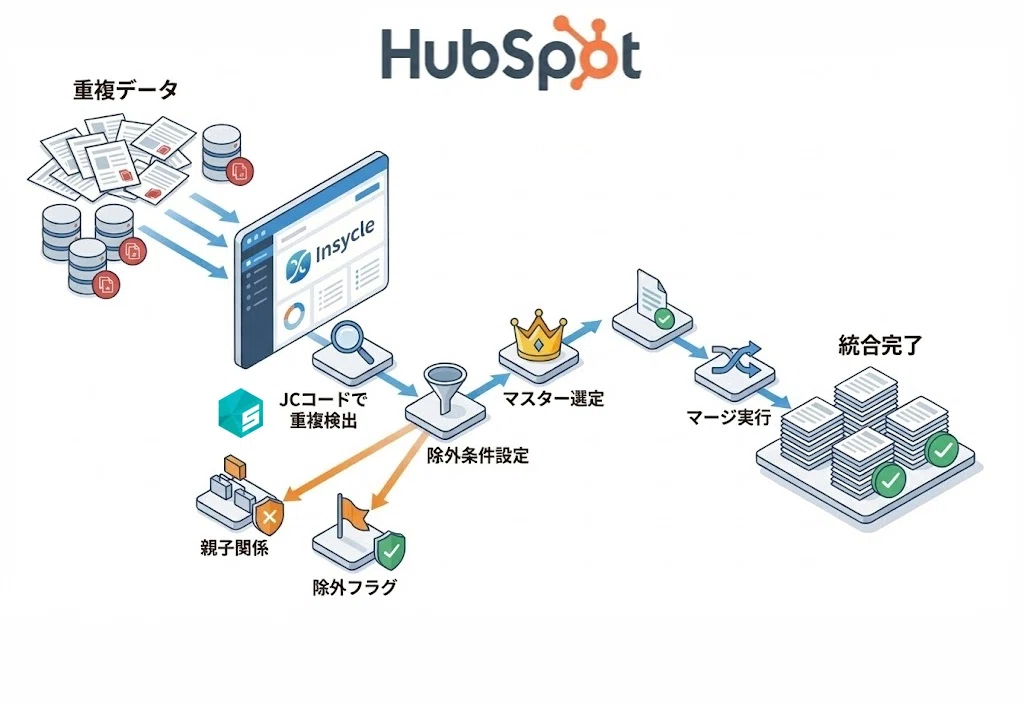
STEP1:カスタムレポートで重複候補を抽出する
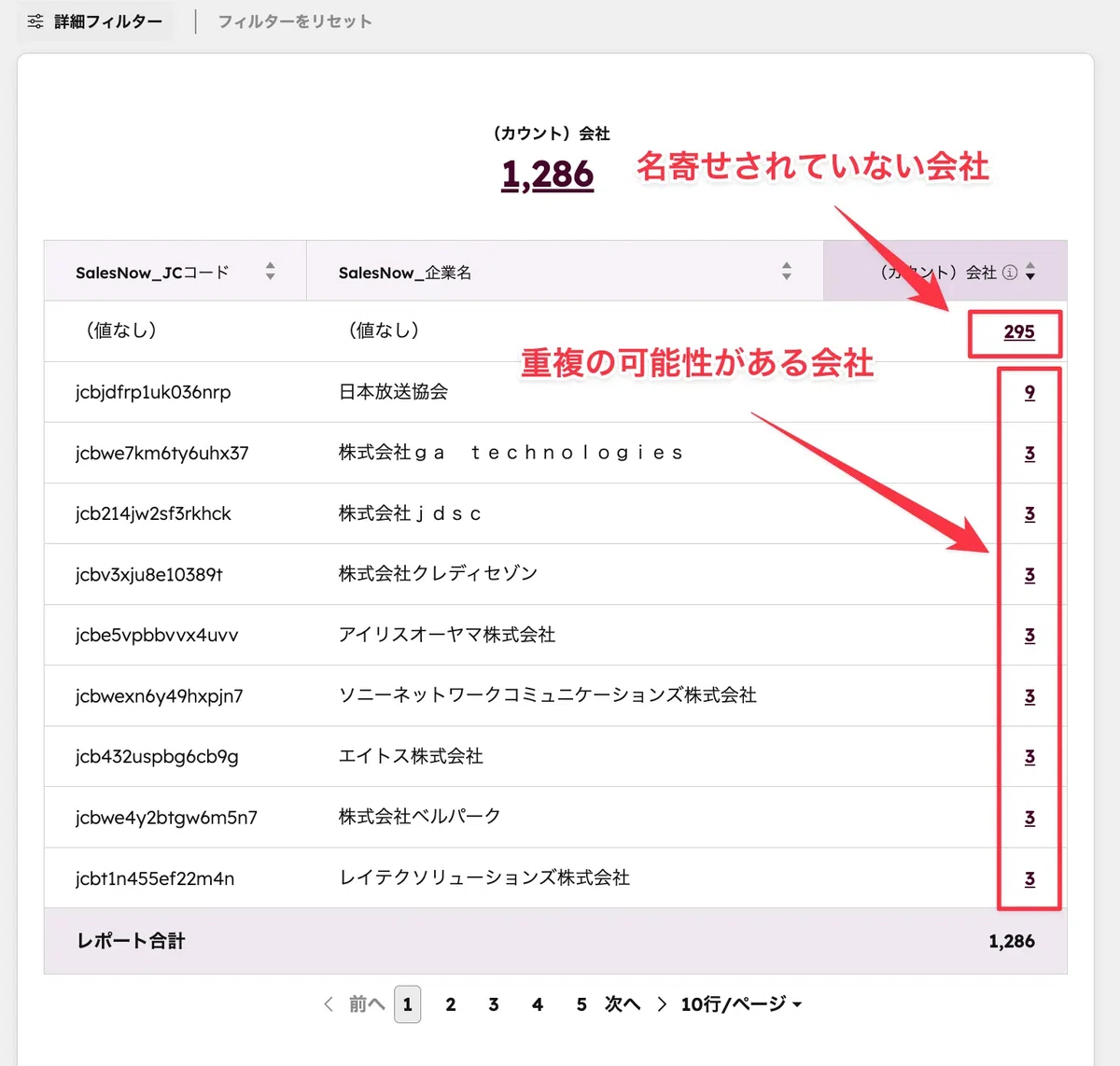
HubSpotのカスタムレポートビルダーで会社レコードを対象にしたレポートを作成します。列に「SalesNow_JCコード」「SalesNow_企業名」「(カウント)会社」を配置し、(カウント)会社降順で並べることで、JCコードが同じ=同一法人とみなされるレコードがいくつあるかを一覧で可視化できます。
STEP2:マージ対象と除外対象を仕分ける
抽出したグループを「マージ対象」(会社名完全一致または表記ゆれ)と「除外対象」(本社と拠点/親子会社など意図した別レコード)に仕分けます。ここで「意図した重複」と「不要な重複」の境界を引いておくことが、後段のフィルター設定の精度を決めます。
STEP3:除外用プロパティ「マージ除外」を準備する
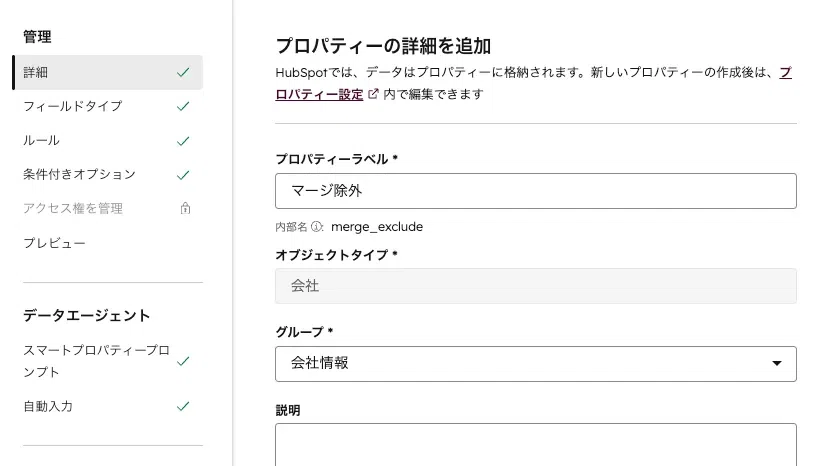
会社オブジェクトに「マージ除外」というチェックボックス型カスタムプロパティを作成します。例外的に統合したくないレコード(例:拠点別管理が必要な企業)に手動でフラグを立てることで、安全装置として機能させます。
STEP4:Insycleをインストール&ログインする
HubSpotマーケットプレイスから「Dedup by Insycle」をインストールします。app.insycle.com にアクセスして「Log in with HubSpot」を選択することで、HubSpotアカウントと連携されます。
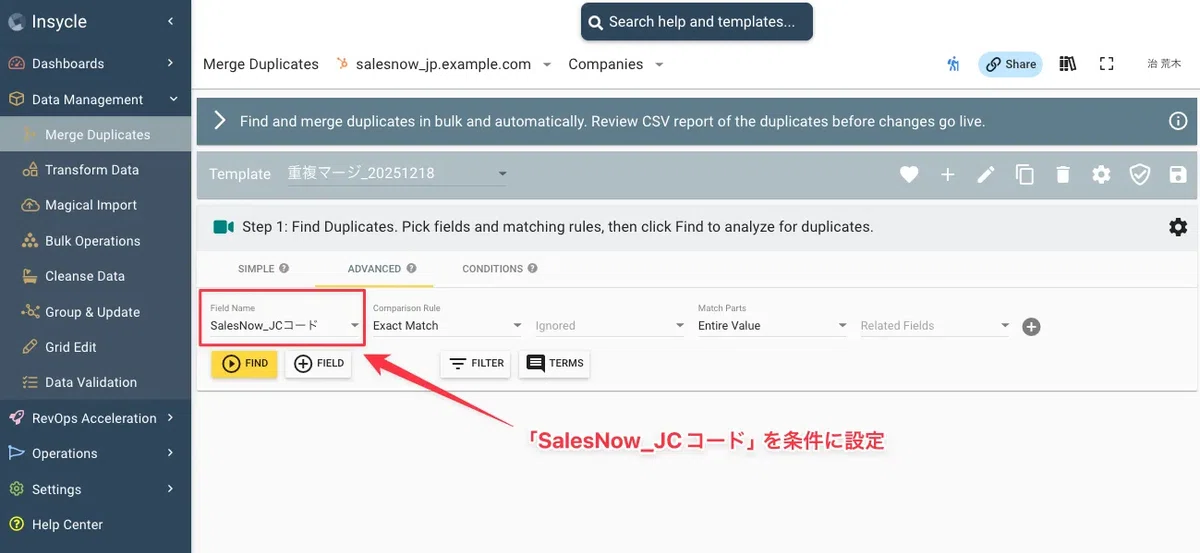
STEP5:Find & Mergeで重複検出条件を設定する
Insycleの「Find & Merge」機能で重複検出条件を設定します。Field=「SalesNow_JCコード」/Comparison Rule=「Exact Match(完全一致)」/Match Parts=「Entire Value(値全体)」とすることで、JCコードが完全一致するレコード群が抽出されます。
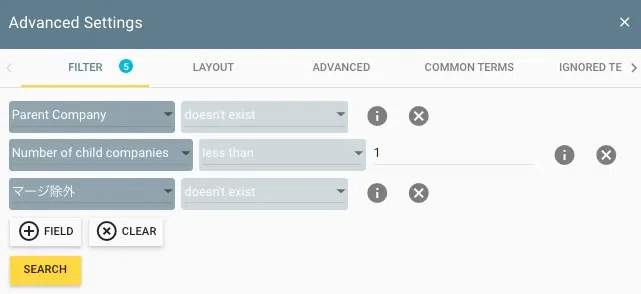
STEP6:FILTERで企業グループ構造を保護する
FILTER機能で除外条件を設定します。「Parent Company doesn't exist」「Number of child companies less than 1」「マージ除外 doesn't exist」の3つを組み合わせ、親子会社関係を持つレコードや手動で除外フラグを立てたレコードを保護します。
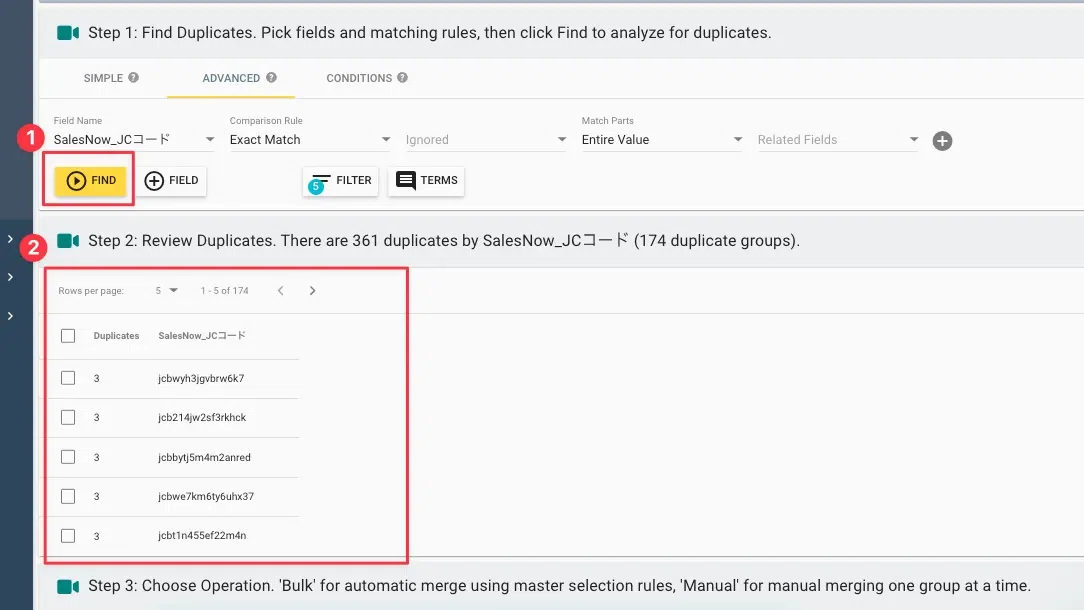
STEP7:FIND実行で対象レコード数を確認する
「FIND」ボタンをクリックすると、条件に合致したレコード群が一覧表示されます。マージ対象数を事前に確認することで、「予想より多すぎる/少なすぎる」場合の条件見直しができます。
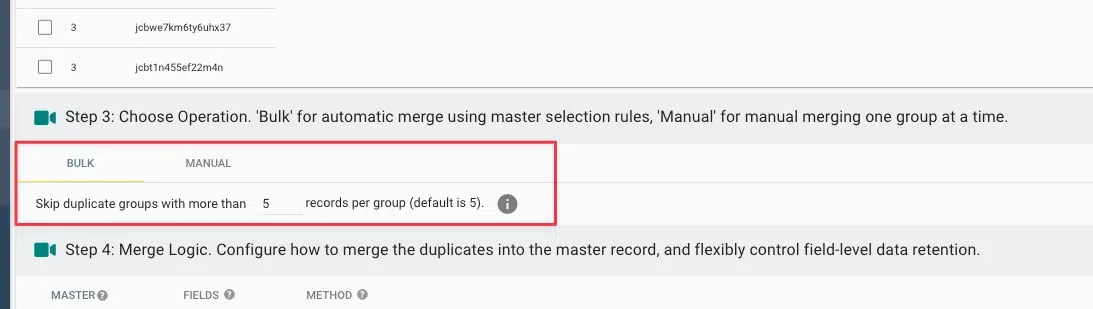
STEP8:BULK処理のマージ上限を「5」に設定する
BULK(一括処理)のマージ上限を「5」に設定します。これは「6件以上の重複は自動でスキップする」という安全装置で、設定ミスや異常データに起因する大規模な誤統合を防ぎます。本番運用で外せない設定です。
STEP9:マスターレコード選定ルールを優先順位で設定する
統合後に残すマスターレコードの選定ルールを優先順位で設定します。①Number of Associated Deals=highest(取引数最多)→②Company owner=exists(担当者あり)→③Create Date=earliest(作成日最古)の順に判定。「By Priority」モードを選ぶことで優先順位通りに評価されます。
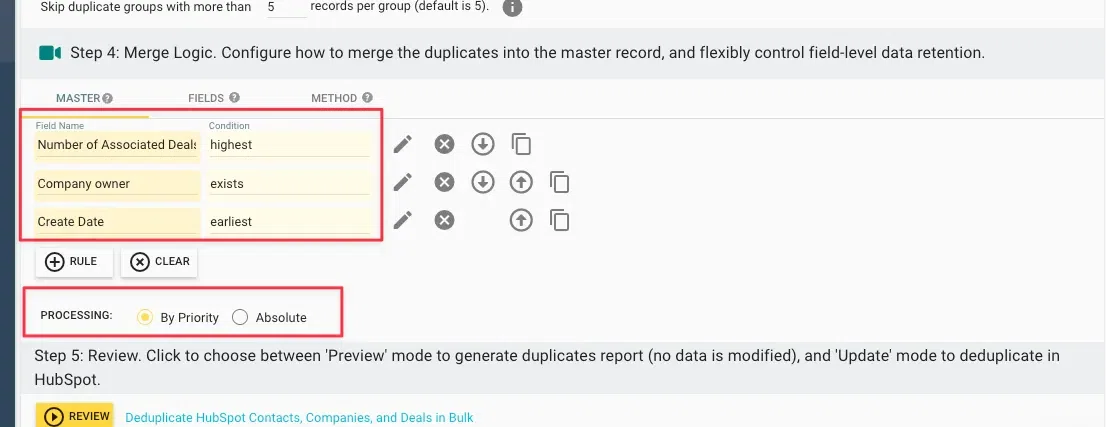
この順番設計は「営業活動の実績が積まれているレコード(取引数最多)を最優先で残す」「次に担当者がアサインされているレコード、最後に作成日が古いレコード」という運用思想を反映しています。
STEP10:REVIEW(Preview検証)でCSVを目視確認してから本番実行する
REVIEW機能でMODE=「Preview」(検証)を選択し、メールアドレスを設定して「Run Now → All」で実行。CSVレポートがメールで届くので、「同一JCコードで正しくグループ化されているか」「別会社が混在していないか」「マスター選定が妥当か」「親子会社が保護されているか」を目視確認します。問題がなければMODE=「Update」に切り替えて本番マージを実行します。
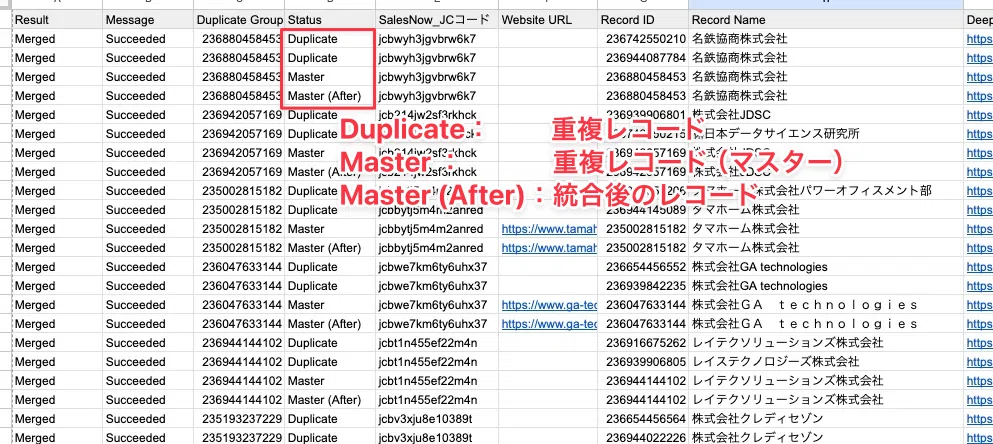
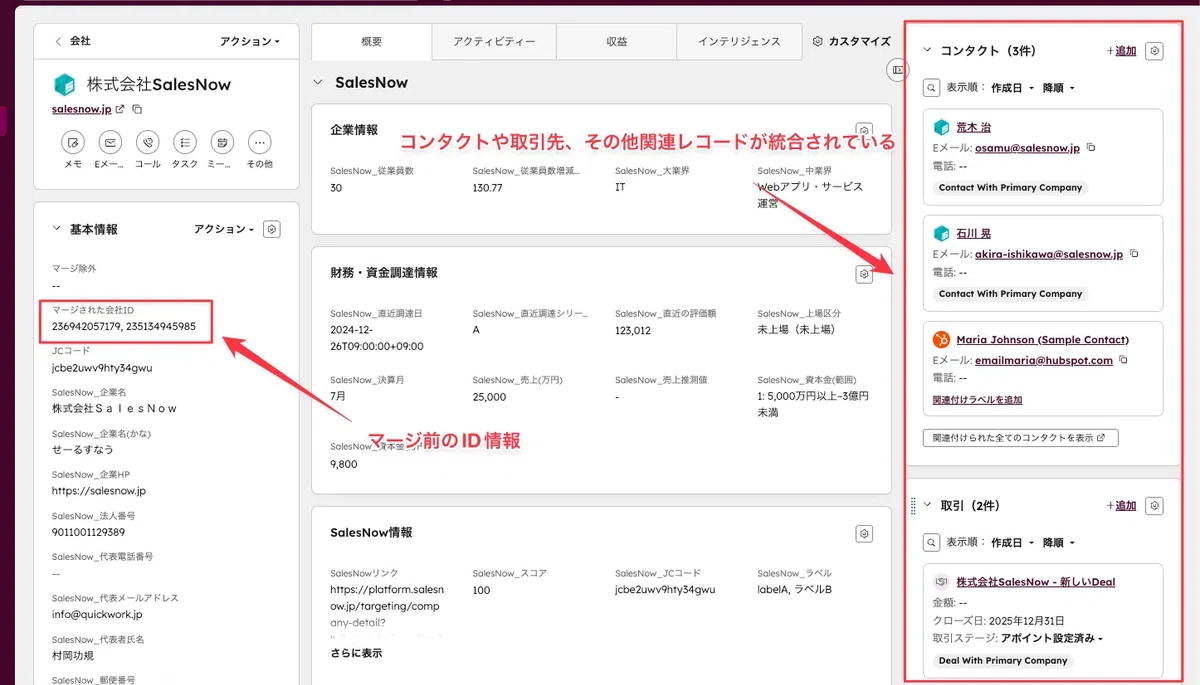
本番運用では、最初に「CHUNK」モードで5件のみテスト実行し、結果を目視確認してから全件実行する流れが安全です。「BULK上限5+Preview→本番」という三段構えで、誤統合事故を構造的に防げます。
実装例3:Salesforce 一致ルール×重複ルールで自動検知を運用化する
Salesforce標準機能の「一致ルール」と「重複ルール」を組み合わせ、SalesNow_JCコードをキーにレコード作成・編集時に自動で重複検知する実装手順です。SalesNow連携のデータ流入を妨げない設定(アラート無効・レポート有効)にすることがポイントで、検知から監視レポートまでを6ステップで構築できます。
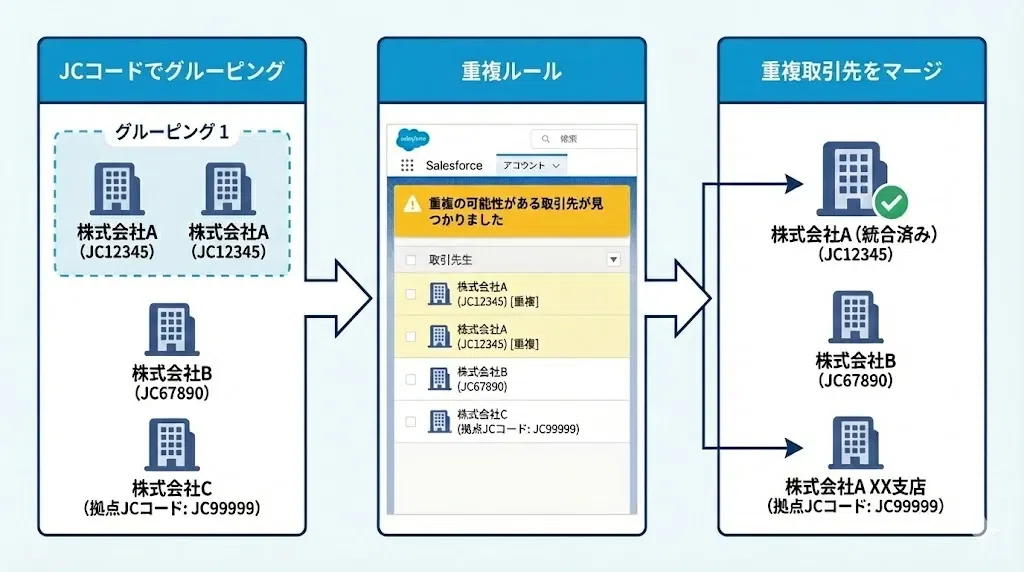
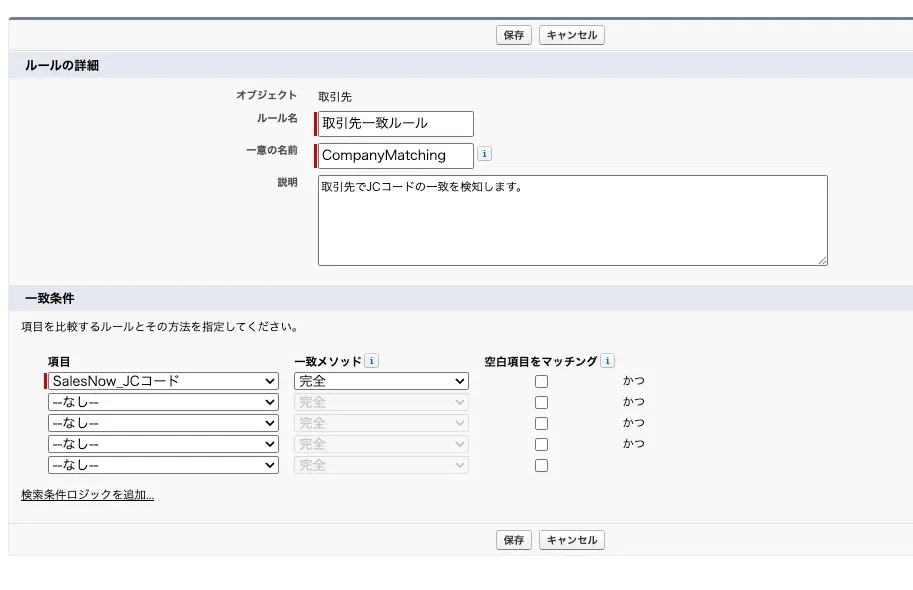
STEP1:一致ルールを作成する(SalesNow_JCコード完全一致)
設定→一致ルール→新規ルールで、対象オブジェクト「取引先」・一致条件「SalesNow_JCコード」・一致メソッド「完全一致」を設定します。JCコードは企業単位でユニークなIDのため、完全一致で正確に判定できます。
STEP2:重複ルールを設定する(SalesNow連携を妨げない設計)
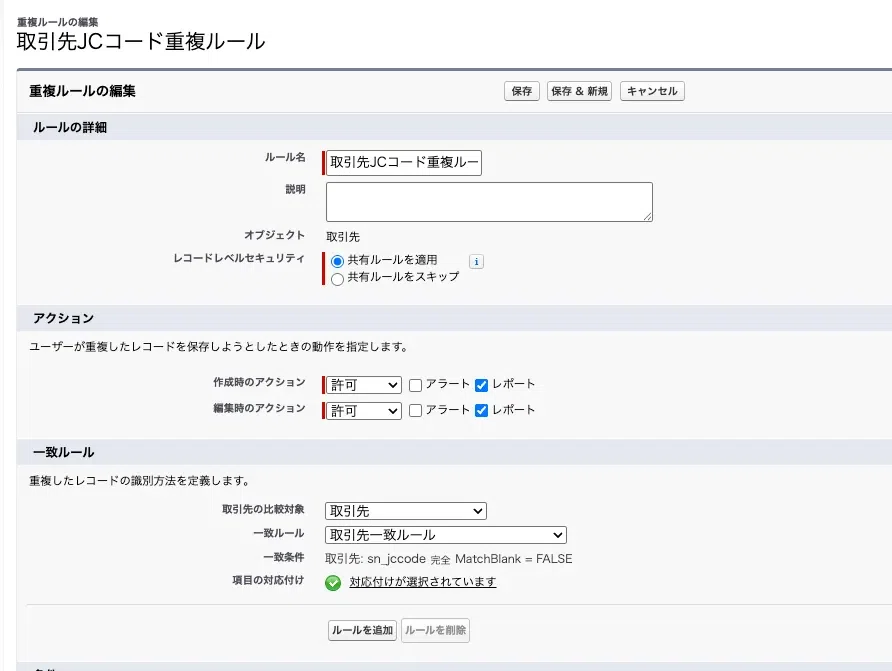
重複ルールでは、作成時/編集時=「許可」(レコード作成を止めない)/アラート=「無効」(ポップアップでSalesNow連携の自動取り込みを邪魔しない)/レポート=「有効」(検知ログは可視化)と設定します。「止めずに記録する」設計がSFA連携運用との両立の鍵です。
| 設定項目 | 値 | 理由 |
|---|---|---|
| 作成時/編集時 | 許可 | レコード作成を止めない(SalesNow連携の自動取り込みを止めない) |
| アラート | 無効 | ポップアップ表示によるSalesNow連携への影響を回避 |
| レポート | 有効 | 検知ログを可視化し、後で監視レポートで一括確認 |
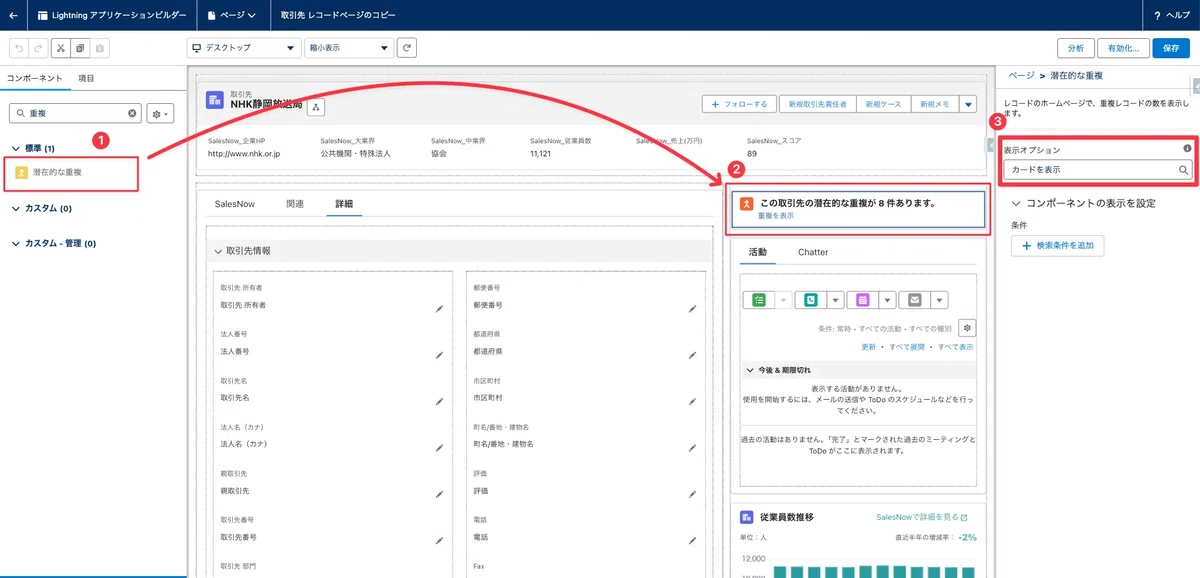
STEP3:「潜在的な重複」コンポーネントを取引先ページに追加する
Lightningアプリケーションビルダーで取引先レコードページを編集し、「潜在的な重複」コンポーネントを追加します。カードオプションで「カードを表示」を選択することで、ユーザーがレコードを開いたときに重複候補が画面上に表示されます。
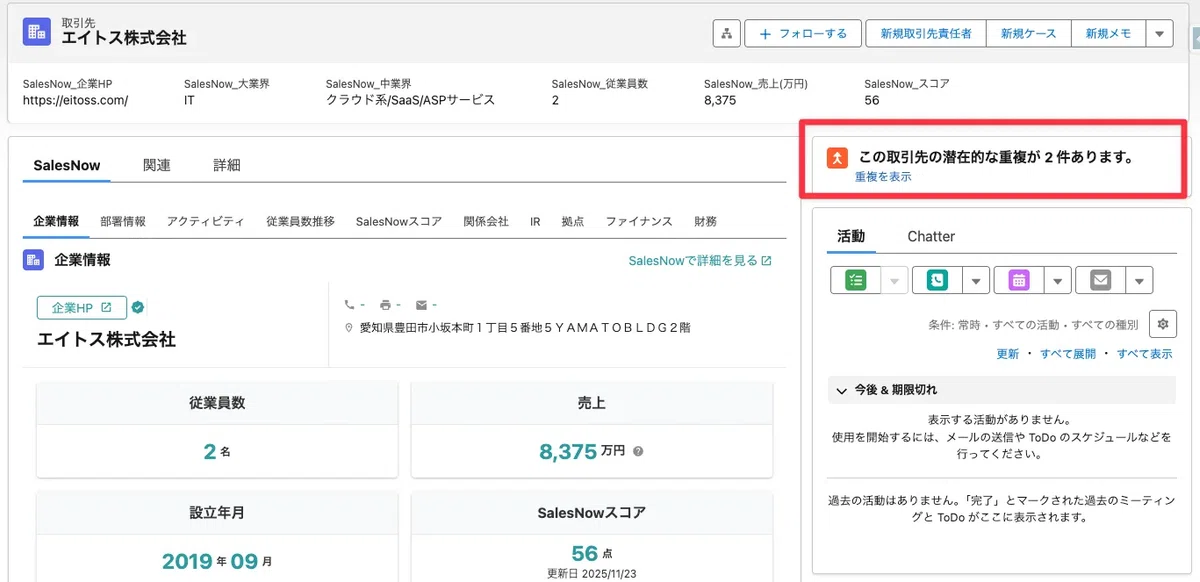
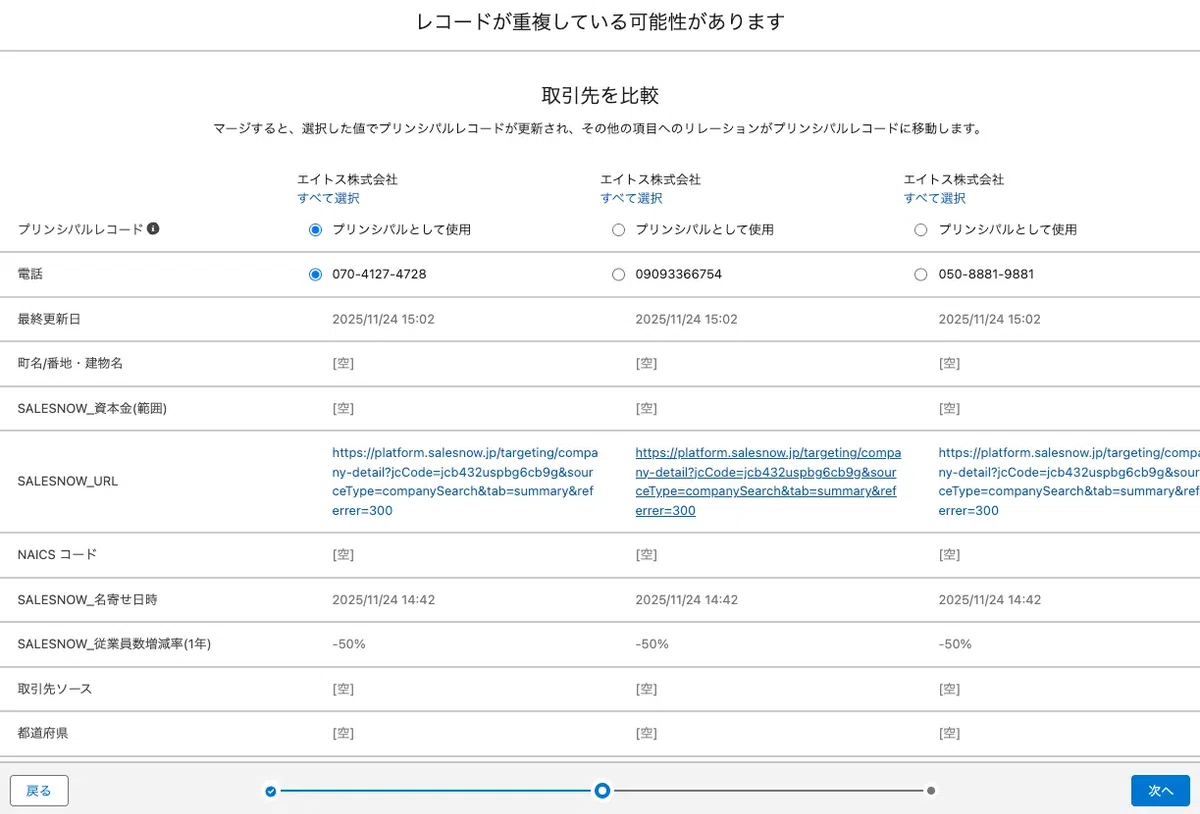
STEP4:マージはウィザード形式で項目単位の値を選択
マージは「統合先選択→項目単位で値を選択→マージ実行」のウィザード形式で進みます。項目ごとに「どちらの値を残すか」を選べるため、「メールアドレスはレコードA、最終連絡日はレコードB」のような細かい判断が可能です。

STEP5:除外条件の追加(拠点別管理を保護)
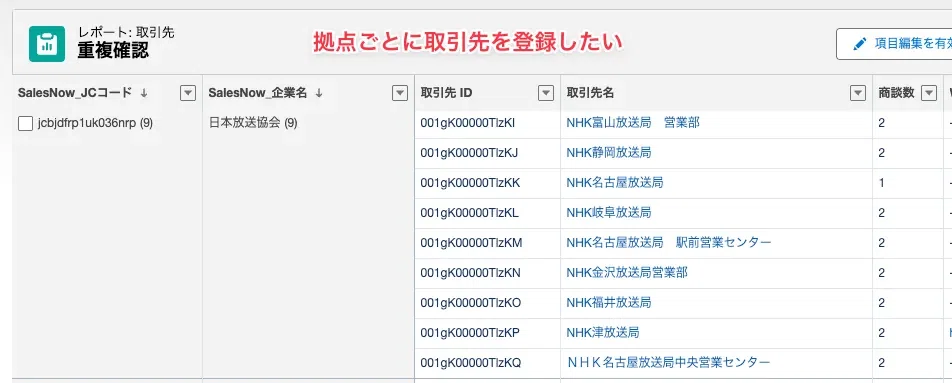
拠点別管理を意図するレコード(例:NHK地方放送局のように、各拠点を独立した取引先として管理したいケース)は、重複ルールで「拠点JCコードが空白でない場合は除外」と設定します。「拠点JCコード」という別項目を作成し、入力されているレコードは重複判定から除外する設計です。
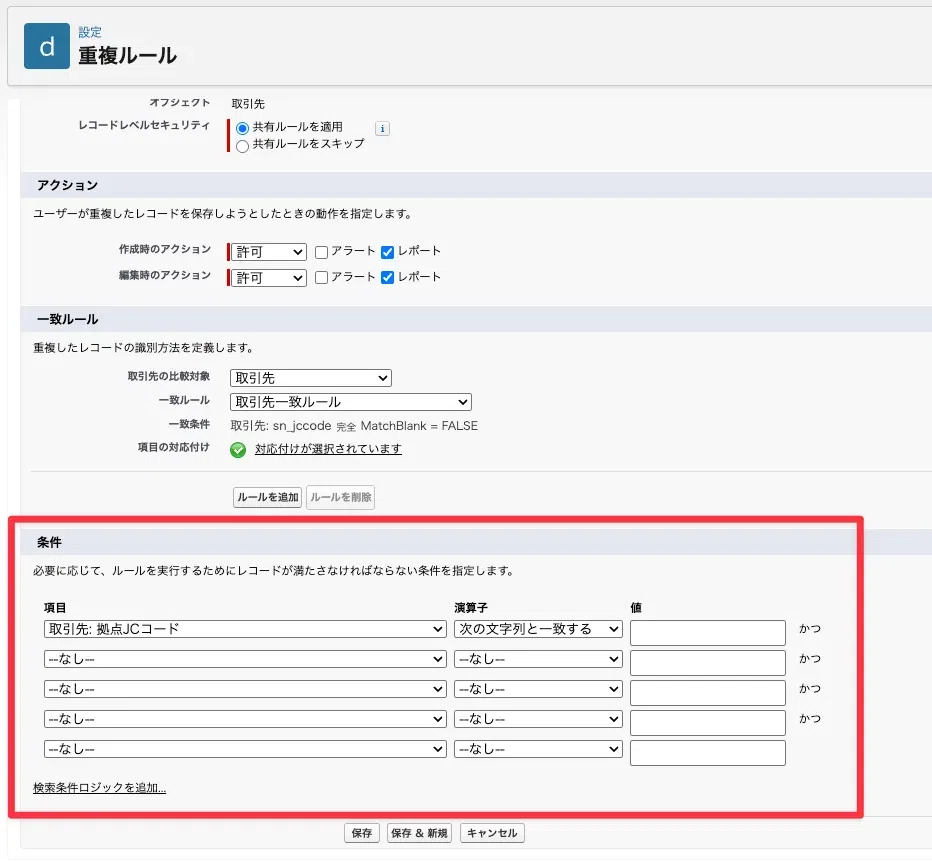
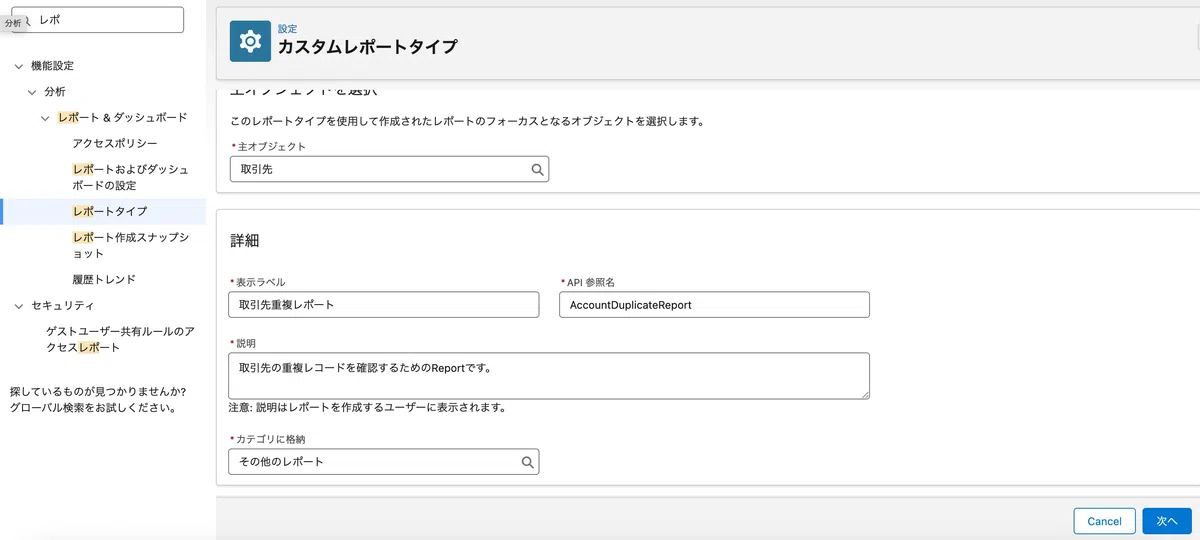
STEP6:監視レポートを構築する(カスタムレポートタイプ)
カスタムレポートタイプを作成し、主オブジェクト「取引先」・関連オブジェクト「重複レコード項目」とすることで、重複ルールが検知したログを一覧で監視できます。日次/週次でこのレポートを見るだけで、「どれくらい重複が発生しているか」「どの拠点に多いか」を把握でき、データ品質改善のPDCAが回ります。
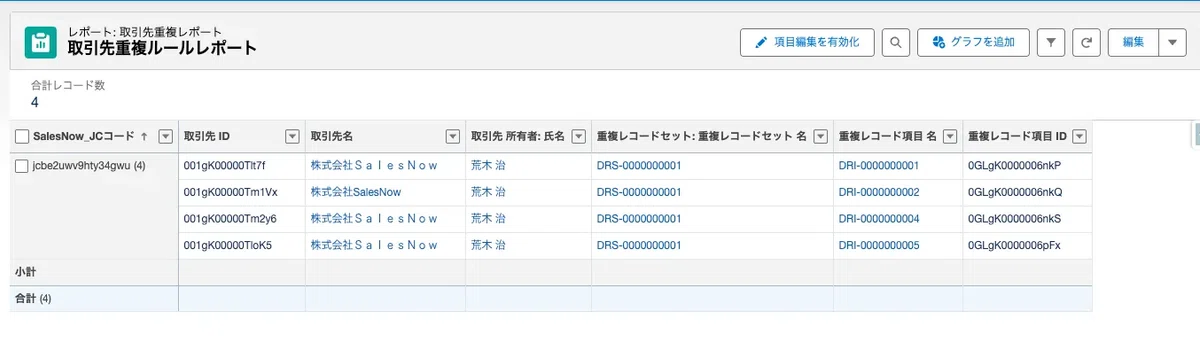
SFA連携への影響を最小化しながら、重複の自動検知と運用監視を両立できる構成です。Salesforce標準機能のみで完結するため、追加コストがかからず、Insycleのような専用アプリと併用する場合も干渉なく運用できます。
SalesNow MCPで自然言語からクレンジング・名寄せを実行する
従来、データクレンジングと名寄せには専用ツールの設定・ルール定義・出力確認といった工程が必要でした。SalesNow MCPを使うと、Claudeなどの生成AIに自然言語で指示するだけで、企業データを参照しながらクレンジングと名寄せを一括処理できます。
SalesNow MCPは、国内1,400万件超の企業データと法人番号情報を生成AIが直接参照できる仕組みです。「このリストの表記ゆれを正規化し、重複を統合して」と指示するだけで、AIが法人番号ベースで判断します。
プロンプト例
「以下の企業リストを、SalesNowの法人データを参照しながら次の手順で整備してください:①表記ゆれの正規化(株式会社の前後表記、半角全角、誤字補完)、②法人番号ベースでの重複統合、③統合結果と判断根拠の出力。」
この指示でAIは、まずデータクレンジングに相当する正規化を行い、続いて法人番号で名寄せ判断を下します。一度の対話で「クレンジング→名寄せ」の2工程をまとめて実行できる点が、従来の個別ツール運用と最も違うところです。
従来手法との違い
- ルール定義が不要:表記ゆれの辞書や正規化ルールを事前に書かなくても、AIが文脈で判断する
- 判断根拠を提示できる:「法人番号一致/所在地一致/代表者名一致」など、なぜ統合したかをAIが自然言語で説明する
- 対話で精度調整できる:「子会社は親会社と統合しない」など追加ルールも自然言語で伝えられる
MCPの仕組みや実装方法は「MCP×企業データ活用ガイド」もあわせてご覧ください。
まとめ
名寄せとデータクレンジングは、営業データ基盤の品質を左右する根本的な取り組みです。
- 名寄せ:分散した同一企業・同一人物のデータを統合する処理
- データクレンジング:表記揺れ・欠損・フォーマット不統一を修正する処理
- 両者はセットで実施し、法人番号を共通キーにすることで精度が最大化される
- 手作業では件数・精度・継続性に限界があり、ツール活用が現実的
SalesNowは1,400万件超の企業データベースを基準に、法人番号を使った高精度な名寄せ・データクレンジングを自動化し、Salesforce・HubSpotとの標準連携で既存SFAのデータ整備を継続的に支援します。名寄せ・データクレンジングは「一度やったら終わり」ではなく、継続的に運用することで初めて営業組織全体の成果底上げにつながります。
あわせて読みたい
よくある質問
Q. 名寄せとデータクレンジングの違いは何ですか?
名寄せとは、複数のシステムや部門に分散した同一企業・同一人物のデータを一つに統合する処理のことです。一方、データクレンジングは、表記揺れ・誤字・欠損・フォーマット不統一などのデータ品質問題を修正する処理を指します。名寄せはデータクレンジングを前提として行われることが多く、両者はセットで実施するのが一般的です。
Q. 名寄せを行うとどのようなメリットがありますか?
名寄せを行うと、SFAやCRMの重複レコードが解消され、顧客データの正確性が向上します。重複アプローチの防止、営業活動の効率化、マーケティング施策の精度向上、正確な売上分析などが期待できます。SalesNow導入企業では、名寄せによってデータ品質が向上し、商談数2.3倍・工数削減8.6時間/人の成果につながった事例があります。
Q. SalesNowはどのように名寄せ・データクレンジングを支援しますか?
SalesNowは国内1,400万件超の企業データベースを基準データとして、Salesforce・HubSpotなど既存SFAのデータを自動で名寄せ・クレンジングします。法人番号を共通キーにした正確な名寄せ、欠損情報の自動補完、表記揺れの統一など、手作業では困難な大量データの整備を自動化できます。